
It’s recommended to read the previous article. If you haven’t, this is the link sciteum.com/2019/09/crsipr-till-today-hmm-what-is-crispr
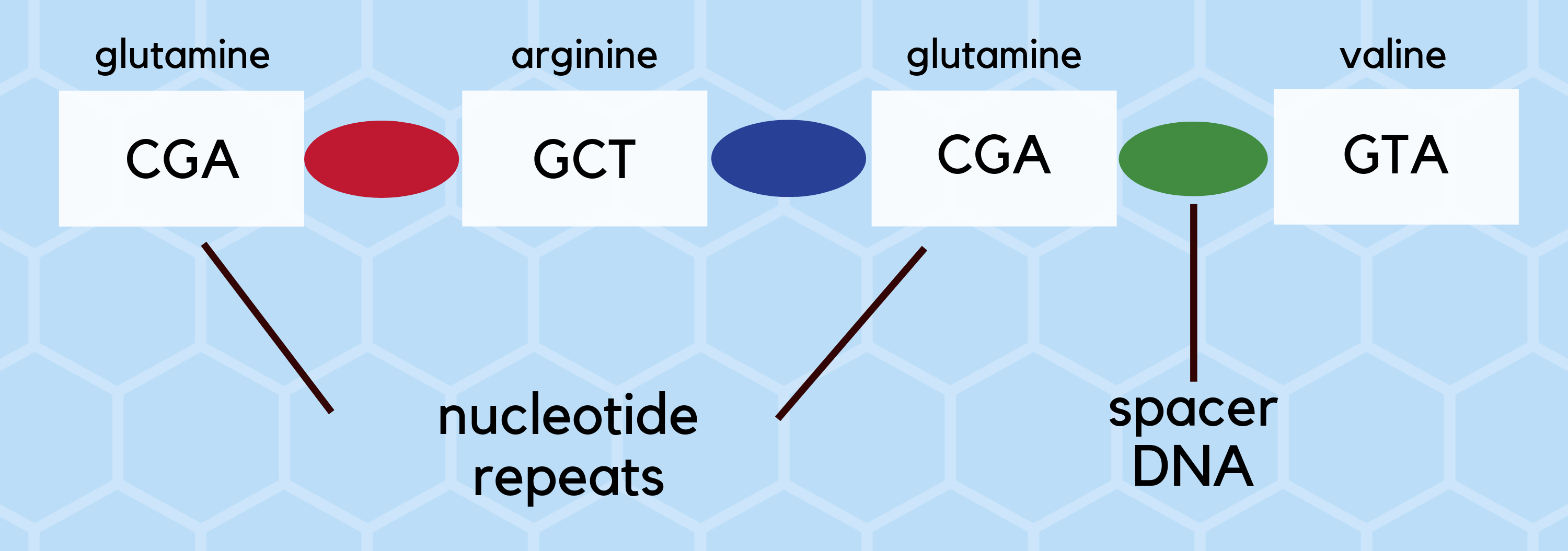
As mentioned in the previous article CRISPR is a specialized region of DNA with two distinct characteristics: the presence of nucleotide repeats and spacers. Umm…. The sequence is like eating fruits and pizzas/burgers consecutive alternate days. Take each item as nucleotide of DNA. Fruits are the nucleotide repeats and pizza is the spacer DNA. Every nucleotides of DNA in a combination of three represents amino acids, the building blocks of protein. Spacer DNA is a non-coding region of DNA between genes, that doesn’t code for any proteins.
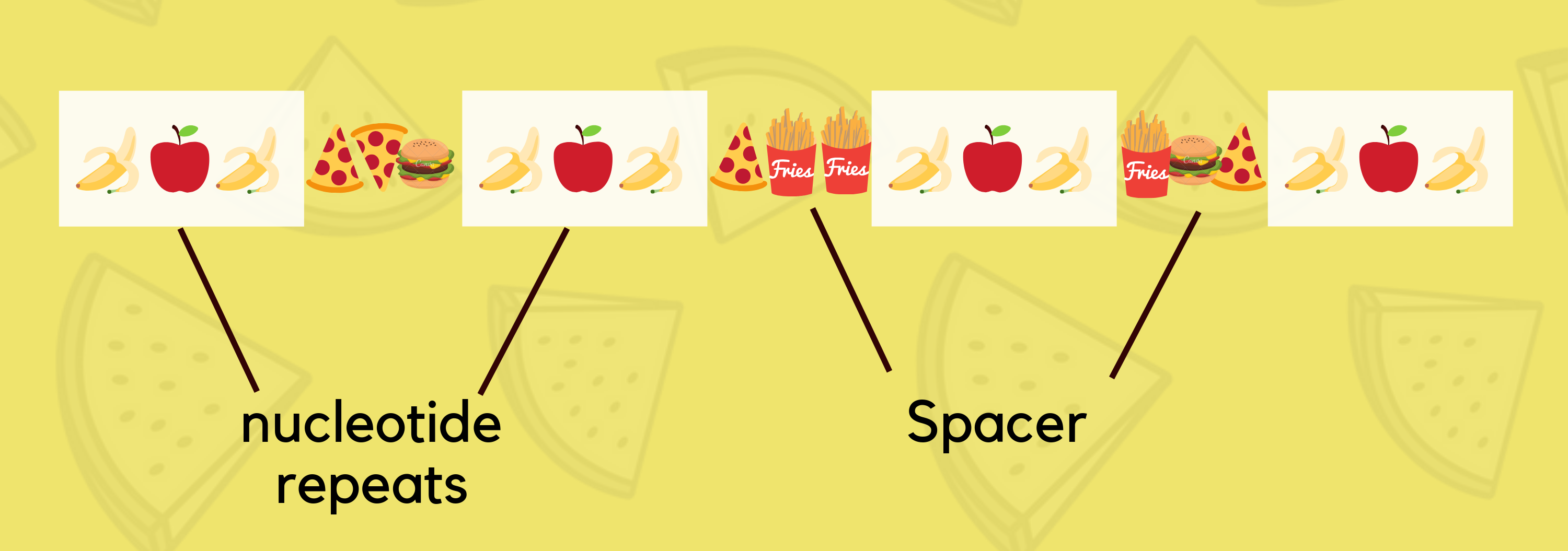
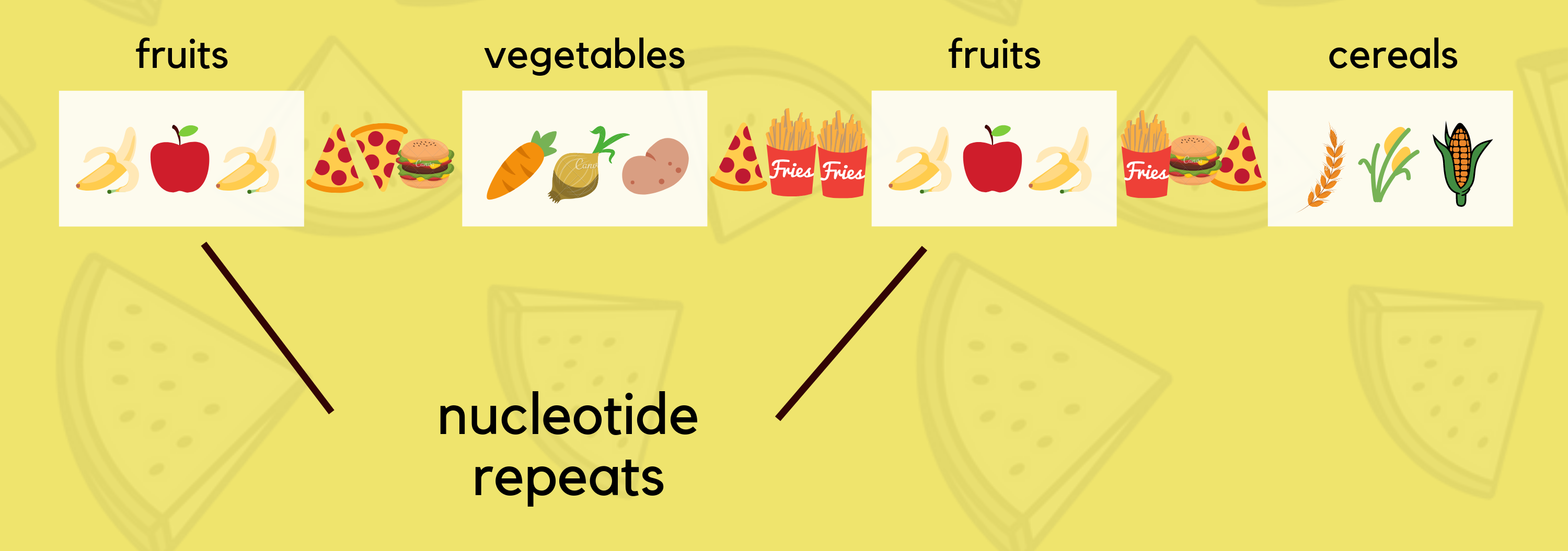
May be, we should look more towards what is repeated sequence! Repeated sequences are patterns of DNA or RNA that occur in multiple copies throughout the genetic material of an organism.
The sequences which codes for same amino acid(s).
Like, bananas and apples code for- fruit; potato, carrot and onion- for vegetable; paddy, corn and wheat for- cereals.
In the case of bacteria, the spacers are taken from viruses that previously attacked it. We can tell this spacers as the memories, which enables bacteria to recognize the virus and fight against it in future. Just, like you will know the difference of taste between pizzas from different shops.
How do this structure help bacteria in fighting of foreign invaders?
Read in the next article.
Article by Moumita Mazumdar

A microbiologist who loves to learn new stuff. Sciteum’s go-to-girl, who not only give suggestions but also fixes the things up. 6 or 60 she communicates in style with all age groups.
One comment